Hash tables, also known as hash maps, are data structures that allow for efficient data storage and retrieval. In computer science, they are often used for operations that call for fast searches, inserts, and removals.In simple words, it maps the keys with the value.
Structure :
Array based storage : Data is stored as an array in a hash table. We call each location in the array as a bucket.
Hash Function : To calculate an index (or hash code) from the key, a hash function is used. The location of the key-value pair in the array is determined by this index.
UML class diagram of a Hash-entry(element)
Structure of a Hash Table
UML classs diagram of a Hash Table
Load Factor : The number of elements kept in a hash table relative to its size determines its load factor. If the load factor is large, the table could be overcrowded, have longer search times, and have collisions. A good hash function and appropriate table resizing can help you maintain an optimal load factor.
Hash Function : A hash function is a function that converts keys into array indices. A good hash function should be used to spread the keys equally throughout the array in order to minimize collisions and guarantee fast search times.
Collision : Two keys might get the same outcome because the hashing technique produces a little number for a big key. When a newly inserted key maps to an already-occupied, collision-handling technology must be used to handle the problem.
Collision in Hash Tables
Handling Collision : Hash tables require a way to handle collisions because it is possible for several keys to create the same hash code (a situation known as a collision). Typical techniques consist of:
Chaining: Every bucket has a list of all key-value pairs that hash to the same index, or it may include another data structure.
OpenAddressing: In the event of a collision, the hash table uses a probing sequence (such as double hashing, quadratic probing, or linear probing) to probe (search) for the next available bucket.
1.1 Operations on Hash Table
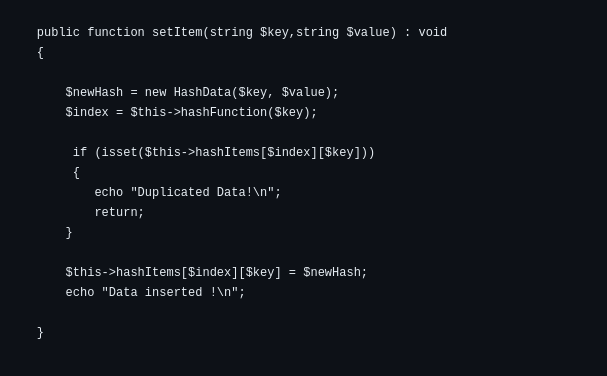
Insertion
An index is generated after the hash function processes the key.
The calculated index is where the key-value pair is stored in the bucket.
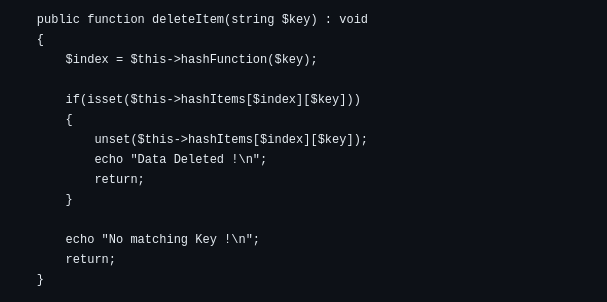
Deletion
The index is calculated through the hash function.
At the determined index, the key-value pair is removed from the bucket.
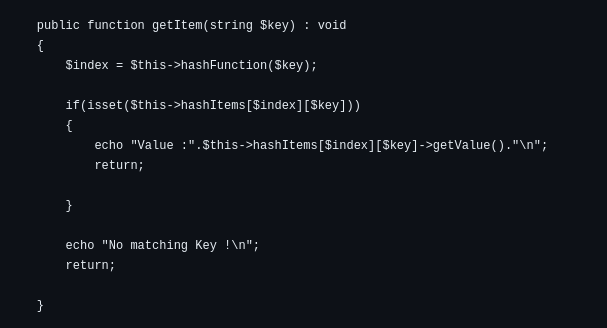
Searching
The index is calculated through the hash function.
At the determined index, the value is retrieved from the bucket
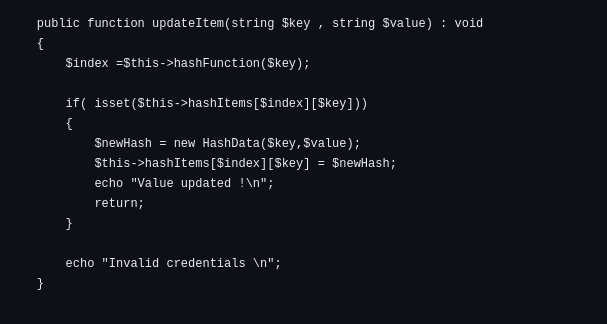
Updating
The index determine from the hash function using the key.
At the determined index, the key-value pair is inserted to the bucket